728x90
반응형
1. 한 일 / 미룬 일
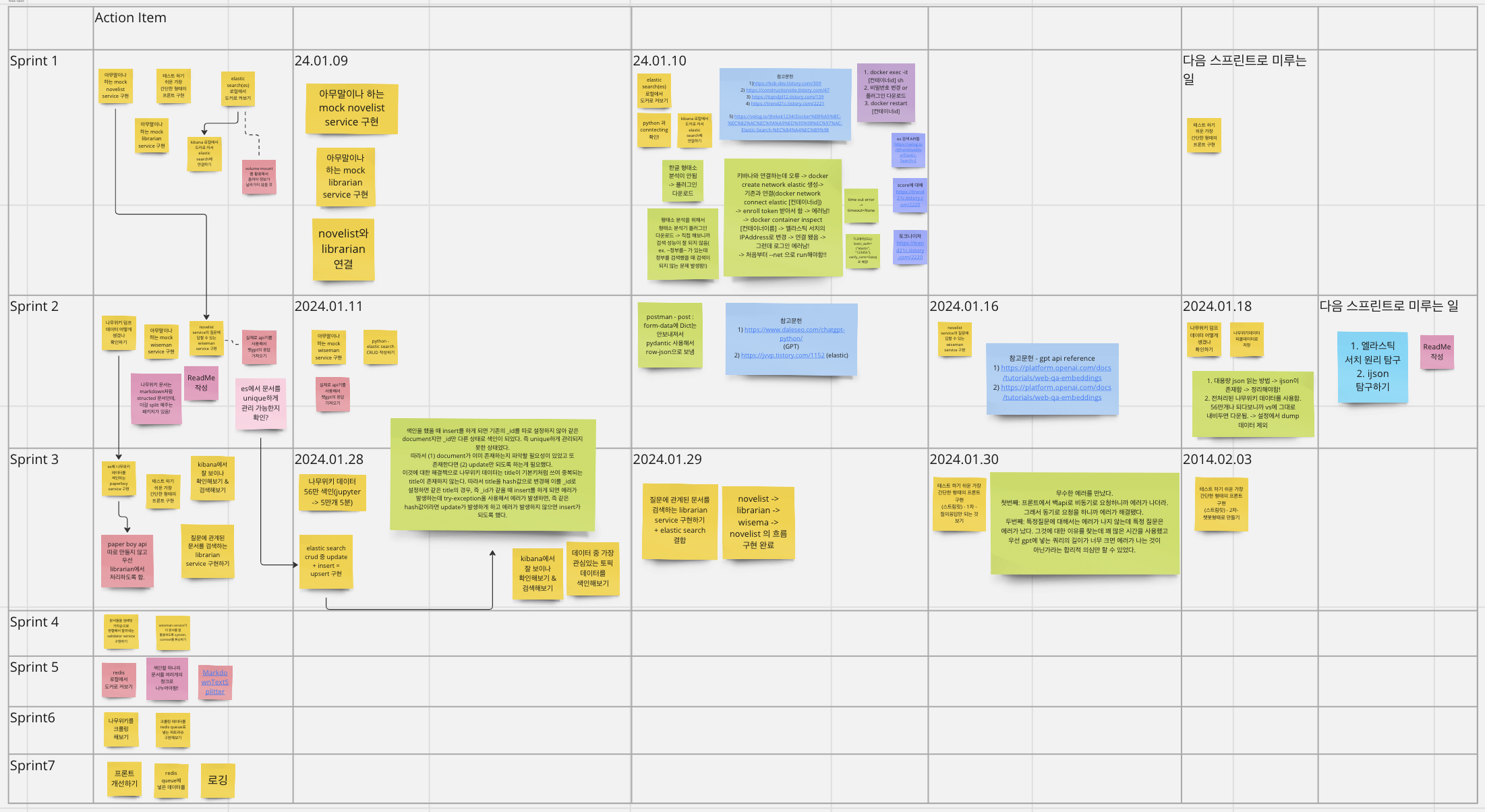
- 기간: 2024.01.28 ~ 2024.02.03
- 나무위키 데이터 elastic search 에 색인
- [sprint2]에서 만든 pickle 데이터를 바탕으로 elastic search 에 색인하는 과정을 거침
- elastic search - upsert 구현
- [sprint2]에서 대략적인 CRUD를 만들어놓기는 했지만 색인하는 과정 중에 문제가 발생.
- 처음에 색인이 되는지 테스트하기 10개 정도의 다큐멘트를 elastic search에 색인하고 테스트 결과 확인 후 1만개의 데이터를 색인.
- 그런데 10010개의 다큐먼트가 생성됨 → 즉, 처음에 테스트용으로 넣어던 데이터가 또다시 색인되는 문제가 발생함
- elastic search에서는 _id라는 인덱스가 생성되는데 내가 설정하지 않았을 때는 MongDB의 ObjectID처럼 자동으로 생성.
- 우리의 목표는 기본키를 적절하게 설정해서 이미 존재하는 다큐멘트의 경우 update를, 새로운 다큐멘트의 경우 insert를 함.
- (내가 못찾은 것일 수도 있지만) elastic search에는 upsert가 존재하지 않아서 직접 구현.
- 나무위키 데이터는 title이 고유하므로 이를 hash값으로 변경해서 인덱스로 설정
- 따라서, 같은 hash값을 가진 경우 이미 존재하는 다큐멘트이므로 update를, 존재하지 않는 다큐멘트의 경우 insert를 할 수 있도록 title을 기준으로한 upsert를 구현함.
- librarian api와 elastic search 연결해서 검색 기능 확인
- front(query) → novelist → librarin → wiseman → GPT -> novelist → front(answer) 흐름 완성. 질문을 넣었을 때 검색 후에 적절한 다큐멘트와 함께 gpt에 요청을 해서 답변을 만듦.
- [ERROR] FastAPI - 422 Unprocessable Enity
- [ERROR] front에서는 key error + wiseman api에서는 400 Bad Requeset 에러
- streamlit을 사용해서 1차, 2차에 걸쳐서 기본적인 chatbot 형태 구현
- streamlit에서 chat_message를 쓰면서 에러가 났었는데..공식문서를 잘 살펴보자.
- 미룬 일
- [ERROR] front에서는 key error + wiseman api에서는 400 Bad Requeset 에러
- 이 에러가 발생한 원인은 token 수가 매우 커서 제공하는 max token을 초과했기 때문이다. 그래서 가격은 비슷하지만 max token 수가 더 큰 GPT 모델로 변경해 1차적으로 해결.
- 하지만 문제는 나무위키에는 확장된 max token보다 더 큰 다큐멘트가 매우 많이 존재하기 때문에 근본적으로 해결하지 못함.
- 따라서, 검색 성능을 유지하면서 어떻게 적절하게 분리시킬 수 있는지 고민해여함.
- [ERROR] front에서는 key error + wiseman api에서는 400 Bad Requeset 에러
2. 회고
- 코테 + 자바 알고리즘 스터디 + 자소서로 인해서 프로젝트가 조금씩 밀리는 경향이 있었다. '미룬 일'은 쉽게 해결될 문제가 아니기 때문에 이 부분은 우선 뒤로 하고 나머지를 구현하는 것을 목표로 하자.
- streamlit 에러때문에 좀 시간을 많이 썼다. chat_message랑 message를 헷갈려서 잘못 쓰는 바람에...공식문서 봤으면 바로 알았을텐데 하필 내가 공부했던 범위 바로 다음 챕터였는데...아무튼 공식문서 잘 활용하는게 매우 중요하다.
- elastic search에서 upsert 구현과 streamlit chat_bot 에 대한 글도 작성해야한다.
728x90
반응형
'프로젝트 > 나무위키LLM' 카테고리의 다른 글
| [ERROR] 왜 key error가 발생했을까? (0) | 2024.01.30 |
|---|---|
| [ERROR] FastAPI - 422 Unprocessable Entity (0) | 2024.01.29 |
| [namu-wiki-llm] sprint2 회고 (0) | 2024.01.19 |
| [namu-wiki-llm] sprint1 회고 (0) | 2024.01.11 |
| [namu-wiki-llm] Elastic Search - 한글 검색 성능 고도화 (0) | 2024.01.11 |



